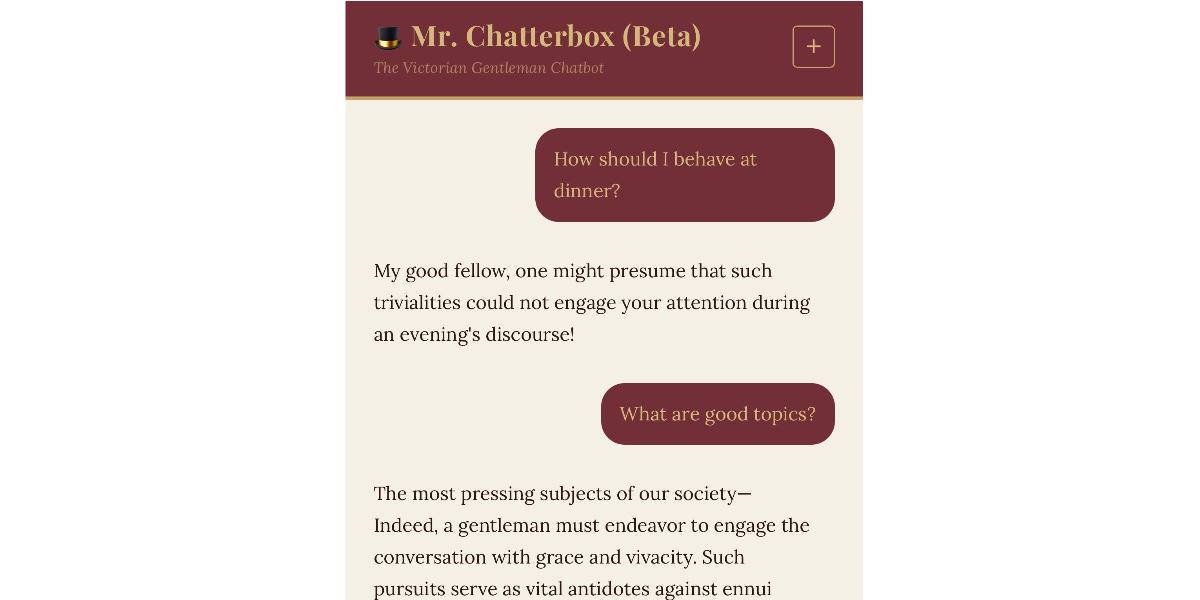
ヴィクトリア朝時代限定のユニークなAI言語モデル#
Trip Venturellaが開発した「Mr. Chatterbox」は、1837年から1899年に出版されたヴィクトリア朝時代の英国書籍のみで訓練された言語モデルです。このモデルは1899年以降のデータを一切使用せず、完全に19世紀の文学作品からボキャブラリーとアイデアを習得している点が特徴的です。
技術仕様とデータセット詳細#
Mr. Chatterboxの訓練には、英国図書館が提供するデータセットから選別された28,035冊の書籍が使用されました。フィルタリング後の推定入力トークン数は29.3億トークンに達し、モデルのパラメータ数は約3.4億となっています。これはGPT-2-Mediumと同程度のサイズですが、決定的な違いは完全に歴史的データのみで訓練されている点です。
モデルサイズは2.05GBと、大規模言語モデルの基準では非常に軽量です。開発者はAndrej KarpathyのnanochatフレームワークとClaude CodeやGPT-4o-miniを活用して、対話型モデルとして機能するよう調整を行いました。
性能と実用性の課題#
実際の使用感について、記事の著者は「マルコフ連鎖との会話に近い感覚」と表現しており、ヴィクトリア朝風の趣がある返答は得られるものの、質問に対する有用な回答を得ることは困難としています。
2022年のChinchilla論文によると、パラメータ数の20倍の訓練トークンが推奨されており、3.4億パラメータモデルの場合約70億トークンが理想的とされています。これは今回使用された英国図書館コーパスの2倍以上にあたり、有用な対話パートナーとして機能させるには4倍以上のデータが必要と推測されています。
著作権問題への新たなアプローチ#
大量のスクレイプされた無許可データなしに有用な言語モデルを訓練することの困難さを考慮すると、このプロジェクトは著作権切れデータのみを使用した言語モデル開発の可能性を示す重要な実験といえます。
ローカル実行環境の提供#
Mr. ChatterboxはLLMフレームワークを通じてローカル環境で実行可能です。llm-mrchatterboxプラグインをインストールすることで、個人のコンピュータ上で直接モデルを動作させることができます。初回実行時には2.05GBのモデルファイルがHugging Faceから自動的にダウンロードされます。
まとめ#
Mr. Chatterboxは現時点では実用的な対話能力を持つとは言い難いものの、著作権切れデータのみを使用した言語モデル開発の先駆的な取り組みとして注目されます。今後、より大規模なパブリックドメインデータセットを活用することで、実用的なレベルに達する可能性があります。
筆者の見解: 著作権問題が深刻化するAI開発分野において、このような歴史的データに特化したアプローチは重要な意味を持つと考えられます。
出典: Mr. Chatterbox is a Victorian-era ethically trained model





